Introduction
The modern software landscape demands high availability, fault tolerance, and rapid deployment cycles. This guide serves as a strategic manual for cloud, platform, and operations engineers aiming to master the Certified Site Reliability Engineer framework. Whether you are transitioning from traditional systems administration, expanding your DevOps capabilities, or leading an engineering department, understanding this structured learning path is essential for scaling modern enterprise systems. By exploring this comprehensive roadmap, professionals can make informed career decisions, align their training with real-world industry requirements, and bridge the gap between theoretical infrastructure management and production-grade reliability engineering. Professionals looking to expand into intelligent operations can also explore specialized tracks via aiopsschool to further enhance their systemic expertise.
What is the Certified Site Reliability Engineer?
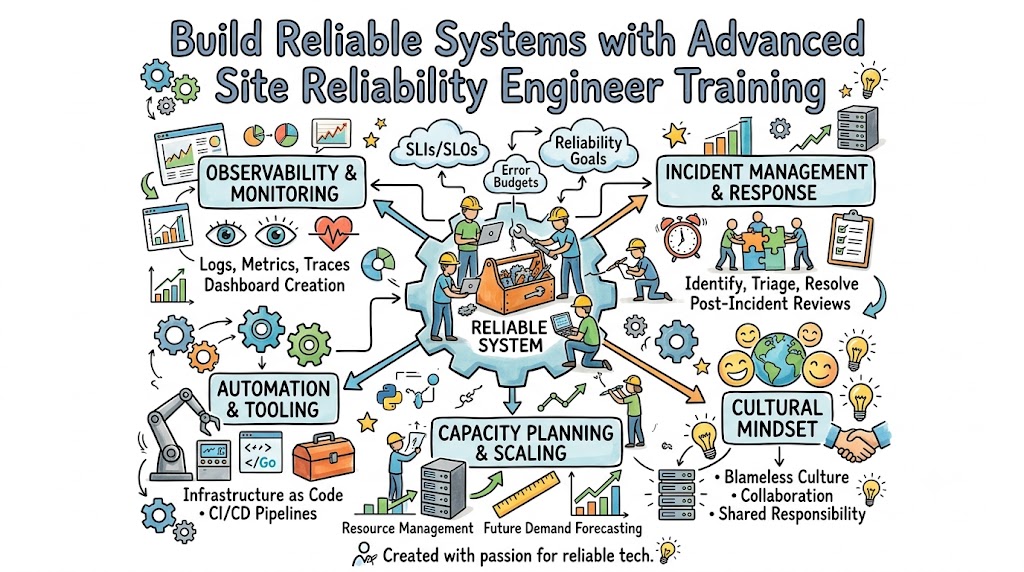
The Certified Site Reliability Engineer program is a professional validation framework designed to measure an engineer’s capability to operate, scale, and secure complex production environments. Unlike traditional certifications that focus solely on cloud provider architectures or specific software tools, this program emphasizes systemic reliability, automation philosophy, and incident management principles. It exists to standardize the core competencies required to treat operations as a software engineering problem.
The curriculum focuses on production-grade execution, ensuring that certified individuals understand the mathematical and architectural foundations of system uptime. Enterprises across the globe utilize this standard to verify that engineers can minimize mean time to resolution and establish robust telemetry pipelines. Ultimately, it bridges the gap between development speed and infrastructure stability.
Who Should Pursue Certified Site Reliability Engineer?
This certification is designed for systems engineers, cloud architects, and software developers who are responsible for the health and performance of production environments. Cloud engineers and DevOps professionals looking to transition into dedicated platform roles will find the structured methodology highly applicable to daily operations. Security engineers and data infrastructure managers benefit significantly by learning how to apply reliability principles to compliance and large-scale data pipelines.
The framework accommodates multiple career stages, offering entry points for junior engineers establishing foundational skills, as well as senior architects designing distributed systems. For engineering managers and technical directors, the program provides the vocabulary and operational metrics needed to lead high-performing engineering teams. Both global enterprises and regional technology organizations recognize this certification as a benchmark for operational excellence.
Why Certified Site Reliability Engineer
In an era defined by microservices, ephemeral infrastructure, and massive data footprints, the demand for structured reliability methodologies continues to outpace availability. Tools, cloud vendors, and frameworks mutate rapidly, but the foundational principles of error budgets, blameless post-mortems, and automation remain constant. This certification provides professionals with timeless architectural strategies that survive shifting technology stacks.
Investing time and effort into this validation yields a high return on career progression by distinguishing general practitioners from true systems specialists. It demonstrates to organizations that an engineer can actively reduce operational overhead and prevent catastrophic downtime. As businesses increasingly rely on digital platforms, possessing a verified capability to protect revenue and maintain user trust is a significant competitive advantage.
Certified Site Reliability Engineer Certification Overview
The certification program is delivered via the official training portal and is hosted formally on the sreschool platform. The assessment approach relies on performance-based scenarios and theoretical evaluations designed to test situational judgment and technical precision. Rather than testing simple memorization, the framework requires candidates to demonstrate a deep understanding of operational trade-offs and architectural bottlenecks.
The ownership and administration of the program ensure that the curriculum remains updated with modern enterprise practices, covering cloud-native ecosystems and hybrid topologies. The structure is broken down into clear operational domains, ensuring a balanced distribution of questions across telemetry, automation, and incident response. This organized approach ensures the credential accurately reflects a candidate’s readiness for real-world engineering challenges.
Certified Site Reliability Engineer Certification Tracks & Levels
The certification framework is divided into three distinct progressive tiers: Foundation, Professional, and Advanced. The Foundation level establishes the baseline nomenclature, covering metrics, basic automation concepts, and core architectural components. The Professional tier shifts the focus toward active implementation, configuration management, distributed tracing, and complex failure domains.
The Advanced level challenges architects to design self-healing infrastructures, lead cross-functional incident responses, and manage organization-wide error budgets. Specialized tracks intersect with these levels, allowing engineers to focus on adjacent domains such as financial operations, security integration, or automated machine learning infrastructure. This granular progression allows professionals to align their certification journey directly with their evolving day-to-day organizational responsibilities.
Complete Certified Site Reliability Engineer Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core Operations | Foundation | Junior Engineers, System Admins | Basic Linux, Networking | SLIs, SLOs, Monitoring, Git | First |
| Systems Engineering | Professional | DevOps Engineers, SREs | Foundation Level, Coding | Automation, Tracing, CI/CD | Second |
| Architecture & Strategy | Advanced | Principal Engineers, Architects | Professional Level, Design | Self-healing, Chaos Engineering | Third |
| Infrastructure Finance | Specialist | FinOps Engineers, Managers | Foundation Level, Cloud Tech | Cost Optimization, Budgeting | Optional |
| Security Operations | Specialist | SecOps, Cloud Security Engineers | Foundation Level, Security | IAM, Vulnerability Scanning | Optional |
Detailed Guide for Each Certified Site Reliability Engineer Certification
Certified Site Reliability Engineer – Foundation
What it is
This certification validates an engineer’s understanding of foundational reliability concepts, basic terminology, and standard operational metrics. It ensures the candidate can articulate the core philosophy of reliability engineering and participate productively in on-call rotations.
Who should take it
Systems administrators, entry-level DevOps engineers, and QA automation professionals seeking to move into production management roles.
Skills you’ll gain
- Defining and calculating Service Level Indicators and Objectives
- Implementing basic synthetic and semantic monitoring
- Understanding log aggregation and metrics collection mechanisms
- Utilizing version control systems for infrastructure tracking
Real-world projects you should be able to do
- Configure a standardized Prometheus and Grafana dashboard for a multi-tier web application.
- Draft an actionable incident alert policy that minimizes notification fatigue based on business impact.
Preparation plan
- 7–14 days: Review official exam blueprints, memorize vocabulary, and complete basic lab exercises on metrics tracking.
- 30 days: Build a localized infrastructure stack, simulate basic microservice components, and generate metric reports.
- 60 days: Dive into case studies of system failures, refine log parsing strategies, and complete multiple comprehensive practice evaluations.
Common mistakes
- Focusing entirely on specific cloud vendor tools rather than generic reliability philosophies.
- Neglecting the mathematical differences between availability calculations and real-world system behavior.
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Professional
- Cross-track option: Certified Cloud Security Specialist
- Leadership option: Systems Engineering Team Lead Certification
Certified Site Reliability Engineer – Professional
What it is
This certification confirms advanced competency in deploying automated infrastructure, managing distributed systems tracing, and executing disaster recovery strategies. It verifies that the engineer can actively minimize human intervention in the deployment pipeline through robust automation code.
Who should take it
Practicing SREs, mid-level DevOps engineers, and system architects responsible for medium-to-large cloud deployments.
Skills you’ll gain
- Writing complex infrastructure as code modules for multi-region systems
- Implementing distributed tracing across decoupled microservices
- Orchestrating blue-green and canary deployment strategies automatically
- Automating disaster recovery procedures and data replication verification
Real-world projects you should be able to do
- Design a fully automated zero-downtime canary deployment pipeline that rolls back based on real-time anomaly detection.
- Build a cross-region failover automation script that syncs transactional database states without human oversight.
Preparation plan
- 7–14 days: Focus on infrastructure as code syntaxes, distributed tracing libraries, and state management mechanisms.
- 30 days: Construct a multi-tier architecture with active-active configurations and write custom health check systems.
- 60 days: Execute continuous load testing profiles, fine-tune tracing configurations, and review advanced network topologies.
Common mistakes
- Hardcoding variables within infrastructure templates instead of building dynamic configurations.
- Overlooking the performance overhead introduced by heavy tracing and profiling agents in production code.
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Advanced
- Cross-track option: Professional Data Architecture Certification
- Leadership option: Technical Program Manager – Infrastructure Track
Certified Site Reliability Engineer – Advanced
What it is
This credential validates an engineer’s capability to architect highly resilient, self-healing software ecosystems and lead systemic organizational turnarounds. It certifies mastery over chaos engineering practices, long-term architectural design, and modern failure domain isolation techniques.
Who should take it
Principal engineers, enterprise infrastructure architects, and senior technical leaders managing systemic reliability operations.
Skills you’ll gain
- Designing distributed patterns that actively isolate cascading system failures
- Constructing automated chaos engineering experiments within production environments
- Developing comprehensive organizational compliance and security guardrails
- Managing organizational error budgets and aligning them with product launch cadences
Real-world projects you should be able to do
- Architect a global, multi-cloud control plane that routes traffic dynamically away from regional outages automatically.
- Implement a structured chaos engineering framework that regularly injects network latency to verify self-healing code paths.
Preparation plan
- 7–14 days: Analyze advanced structural architecture patterns, queueing theories, and consensus algorithms like Raft or Paxos.
- 30 days: Build a simulated distributed system, run targeted fault injection routines, and evaluate systemic response boundaries.
- 60 days: Author organizational policies, practice post-mortem leadership simulations, and conduct rigorous technical audits of architectural flaws.
Common mistakes
- Designing overly complex self-healing systems that accidentally trigger secondary, unexpected outages.
- Failing to align operational metrics with actual customer experience indicators.
Best next certification after this
- Same-track option: Continuous Enterprise Resilience Fellow
- Cross-track option: Enterprise FinOps Director Certification
- Leadership option: Principal Infrastructure Director Program
Choose Your Learning Path
DevOps Path
This framework concentrates on the seamless bridge between software delivery and system operations. Engineers learn to integrate robust continuous delivery structures with precise telemetry architectures. The focus remains on shortening development cycles while ensuring that system updates do not destabilize existing infrastructure components.
DevSecOps Path
Security cannot exist as an afterthought in modern production environments. This track infuses automated vulnerability scanning, identity management, and compliance checking directly into the engineering loop. Professionals ensure that infrastructure remains completely locked down without reducing deployment velocity or throttling scaling operations.
SRE Path
The core reliability track emphasizes systemic availability, automation, and incident mitigation strategies. Engineers learn how to manage infrastructure using code principles, govern error budgets, and perform root-cause diagnostics on complex distributed failures. This creates a standard operational structure focused on application uptime and performance.
AIOps Path
This learning track focuses on integrating anomaly detection models and automated pattern recognition engines directly into monitoring loops. Engineers learn how to process massive metric streams using advanced mathematical processing models to identify hidden infrastructure defects before they escalate. It modernizes operations by reducing manual dashboard interpretation.
MLOps Path
Operating machine learning workloads at scale requires specialized infrastructure pipelines. This path addresses model deployment tracking, data drift monitoring, and training cluster resource allocation. Professionals master the unique challenges of keeping compute-heavy artificial intelligence workloads running smoothly across distributed clusters.
DataOps Path
Data pipelines require high reliability to ensure analytical processing correctness. This route provides the methodologies needed to monitor distributed data warehouses, object storage layers, and message streaming clusters. Engineers learn to treat data flow as a standard production application with strict quality and delivery metrics.
FinOps Path
Cloud expenditures can spiral out of control without clear oversight. This path intersects infrastructure architecture with financial accountability, showing professionals how to design cost-efficient infrastructure systems. Engineers gain the capability to tag resources precisely, identify idle compute patterns, and size cloud instances correctly.
Role → Recommended Certified Site Reliability Engineer Certifications
| Role | Recommended Certifications |
| DevOps Engineer | Certified Site Reliability Engineer – Foundation, Professional |
| SRE | Certified Site Reliability Engineer – Foundation, Professional, Advanced |
| Platform Engineer | Certified Site Reliability Engineer – Professional, Advanced |
| Cloud Engineer | Certified Site Reliability Engineer – Foundation, Professional |
| Security Engineer | Certified Site Reliability Engineer – Foundation, DevSecOps Specialist |
| Data Engineer | Certified Site Reliability Engineer – Foundation, DataOps Specialist |
| FinOps Practitioner | Certified Site Reliability Engineer – Foundation, FinOps Specialist |
| Engineering Manager | Certified Site Reliability Engineer – Foundation, Management Track |
Next Certifications to Take After Certified Site Reliability Engineer
Same Track Progression
Once the core reliability certifications are completed, engineers should pursue deep architectural specializations. This involves focusing on hyper-scale infrastructure configurations, deep storage subsystem mechanics, and global network routing optimizations. Moving higher within this path establishes a professional as an authority on planetary-scale system availability.
Cross-Track Expansion
Expanding horizontally allows engineers to master adjacent domains like specialized security compliance or extensive data pipeline architecture. Combining core reliability skills with specialized cloud computing mechanics creates a multi-faceted engineer capable of leading cross-functional infrastructure initiatives. It broadens professional value across varying corporate models.
Leadership & Management Track
Transitioning from purely technical execution to organizational strategy requires a firm grasp of business alignment and human management. Future directors choose certifications that teach them how to transform operational metrics into fiscal outcomes. This transition equips leaders to build resilient technical cultures, scale human teams, and manage capital budgets effectively.
Training & Certification Support Providers for Certified Site Reliability Engineer
DevOpsSchool delivers immersive, instructor-led training modules tailored to modern software delivery paradigms. Their interactive labs provide engineers with hands-on practice building reliable delivery pipelines and containerized applications.
Cotocus provides targeted corporate upskilling programs focusing heavily on production architecture patterns. They assist mid-sized and large enterprises in migrating engineering staff toward reliability-focused delivery frameworks.
Scmgalaxy functions as a massive community hub and repository for configuration management strategies and continuous delivery guides. It offers extensive reference implementations for troubleshooting complex system deployments.
BestDevOps structures its curriculum around real-world deployment challenges and infrastructure as code testing practices. Their training scenarios prepare engineers for complex technical evaluations.
devsecopsschool focuses exclusively on blending automated security mechanisms into modern operations workflows. Their material ensures compliance frameworks are verified continuously inside production environments.
sreschool stands as the definitive training architecture provider for the core reliability engineering certifications. Their simulated lab environments accurately mimic enterprise system failures.
aiopsschool bridges the gap between infrastructure metrics and automated pattern recognition frameworks. They prepare engineers to deploy intelligent analysis engines across noisy infrastructure environments.
dataopsschool focuses training paths entirely on the data delivery pipeline ecosystem. Their modules teach professionals to track data lineage, state drift, and distributed processing cluster health.
finopsschool specializes in training engineers to analyze cloud consumption footprints and manage infrastructure spending. Their courses align engineering architecture choices with corporate fiscal responsibility.
Frequently Asked Questions (General)
- What is the primary difference between standard DevOps and specialized reliability engineering tracks?DevOps focuses heavily on breaking down silos between development and operations teams to accelerate code deployment speeds. Reliability engineering acts as a specific implementation of DevOps that treats operations entirely as a software engineering problem, prioritizing system resilience and uptime.
- How long does it typically take to complete the professional level evaluation?A typical engineer with an active background in infrastructure management can expect to spend thirty to sixty days preparing for the professional tier evaluation. This timeframe allows for a deep dive into complex lab scenarios and infrastructure as code testing patterns.
- Are coding skills required to successfully pass the advanced tier examinations?Yes, the advanced level requires a strong grasp of software engineering principles, as candidates must analyze automation scripts, interpret distributed traces, and design self-healing application code blocks.
- Can an engineering manager benefit from pursuing the foundational course track?Absolutely, the foundational track provides technical leaders with the concrete vocabulary, operational metrics, and structural framework required to evaluate and guide engineering teams effectively.
- How long do these technical certifications remain valid before requiring recertification?The certifications carry a standard validity window of three years, after which professionals must complete an update assessment or demonstrate continued engagement in the field.
- Are there any hard prerequisites required before registering for the advanced level exam?Candidates must successfully pass the professional tier assessment and demonstrate verifiable experience working within distributed production environments before unlocking the advanced examination module.
- How does this training framework map to multi-cloud enterprise architectures?The principles taught are entirely cloud-agnostic, focusing on underlying systemic mechanics, network topologies, and tracing strategies that apply uniformly across all major public and private cloud providers.
- What types of assessment methods are used during the formal examination process?The evaluation combines situational judgment questions, architecture design analysis, and performance-based simulation exercises to measure practical execution capabilities.
- Does the program cover automated cost optimization strategies along with uptime metrics?Yes, specialized modules within the framework address cloud asset optimization, resource tagging structures, and strategic financial planning for infrastructure.
- How does this certification handle modern container orchestration platforms like Kubernetes?Container orchestration and cloud-native application architectures form a core pillar of both the professional and advanced tracks, reflecting standard enterprise deployments.
- Is there an active community support network available for candidates during the preparation phase?Candidates gain access to dedicated support channels, study groups, and community repositories managed across the provider hosting networks.
- What is the return on investment for an organization sponsoring this training path for their staff?Organizations experience a noticeable reduction in severe production outages, lower mean time to resolution metrics, and a more streamlined, automated deployment pipeline.
FAQs on Certified Site Reliability Engineer
- How does the Certified Site Reliability Engineer program directly address incident management?The curriculum focuses deeply on setting up blameless post-mortem frameworks, establishing actionable alerting criteria, and minimizing mean time to detection. It shifts engineering teams away from chaotic firefighting toward structured, automated root-cause isolation workflows.
- Is it necessary to complete the foundation course if I have years of experience?While experienced engineers might understand basic terms, starting at the foundation level guarantees alignment with specific framework methodologies and metrics calculations used in later tiers.
- Does the Certified Site Reliability Engineer curriculum include chaos engineering practices?Yes, chaos engineering is a major focal point within the advanced track, where engineers learn to safely inject infrastructure faults to verify system resilience.
- How are the practical lab exercises structured within the sreschool platform?The labs run within isolated cloud sandboxes where real production failures are simulated, requiring candidates to diagnose and repair live infrastructure bottlenecks.
- Does this certification help in transitioning from a traditional sysadmin to an SRE role?It provides the exact software-centric operational mindset and automation skills required to successfully make that specific career transition.
- What metric philosophies are prioritized throughout the Certified Site Reliability Engineer training?The program prioritizes user-centric performance metrics, focusing on how internal system indicators map directly to real-world application availability.
- Are open-source observability tools emphasized over proprietary monitoring suites?The framework focuses on industry-standard open-source tools to ensure engineers learn universal observability mechanics rather than proprietary interfaces.
- Can this certification path be completed entirely through self-paced learning models?Yes, the platform supports comprehensive self-paced learning paths alongside structured instructor-led options to accommodate varying professional schedules.
Final Thoughts: Is Certified Site Reliability Engineer Worth It?
Investing time in professional validation should always be driven by practical utility rather than career hype. The Certified Site Reliability Engineer framework offers genuine value because it focuses on systemic principles rather than ephemeral software tools. It demands that you think like an engineer when systems break, evaluating architectural trade-offs using data rather than intuition.
If your daily goals include reducing engineering overhead, scaling infrastructure cleanly, and protecting production platforms from critical failures, this path provides the necessary structured clarity. It elevates an engineer’s capability from basic server configuration to complex system resilience orchestration. Ultimately, the industry values professionals who can keep complex platforms stable under heavy load, making this a highly practical and durable career investment.